我对富文本编辑器最初的印象可能停留在 UEditor、CKEditor 这类编辑器上,如下所示
2018 年入职 Workitle 后,接触到 Worktile 中在线网盘的功能,感觉在线网盘简直太好用了,Markdown 语法让你不太需要考虑排版问题就可以写出结构良好的文章
在 2019 年 8 月份左右的时候,我们开始开发自己的知识库产品 PingCode Wiki,然后对于在线文档、知识库以及背后的富文本编辑器技术都有了更深刻了解和认识,我也算是正式入坑富文本编辑器领域,也因此找到了可以持续学习和努力的方向。
PingCode Wiki 提供结构化知识库来记载信息和知识,便于团队沉淀经验、共享资源,欢迎各位来体验!
聊聊富文本编辑器之伤
大家公认的富文本编辑器领域在前端里面是天坑的存在。
总结下就是存在一个矛盾:
落后的生产力与人们日益增长的需求之间的矛盾
落后的生产力:
- 编辑内容相关标准推进缓慢
- 浏览器厂商对于相同操作或者场景实现方式的不同,导致兼容性的问题
- 使用 HTML DOM 描述富文本内容有太多不可控制的情况
日益增长的需求:
- 不确定的交互意图,比如按 Delete 键,不同的焦点位置有不同的情况需要考虑
- 内容输入的多样性,比如有:打字键入、粘贴、拖拽等,每个处理起来都相当复杂
- 大量需要拦截阻止和代理的浏览器默认行为,保证数据的完整性和正确性
- 用户对于编辑器的使用要求越来越高,比如:合并单元格、列表多级嵌套、协同编辑、版本对比、段落标注,大家都认为这是基本需求,其实这里面的技术难度是超出大家的想象的。
开源富文本编辑器技术
尽管标准不完善,但是通过开源还是让编辑器技术得以沉淀和发展,这里我主要从技术实现以及编程思想的演变,介绍编辑器这 10 年间的变化与发展。
大概要说到下面这几款编辑器:
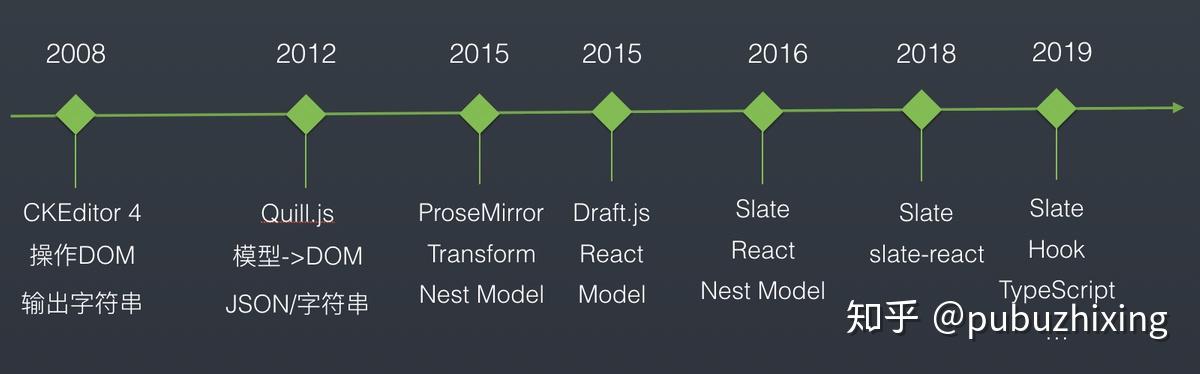
CKEditor 1-4(2008)
UEditor (2012)
Quill.js(2012)
CKEditor 5(2014)
Prosemirror(2015)
Draft.js(2015)
Slate(2016)
因为每一款编辑器想研究明白都需要花费几个月甚至半年的时间,所以这里主要说说我对这些编辑器的一个理解,介绍下他们的特点以及他们之间的区别,点到为止。
编辑器技术阶段划分
通常大家把编辑器技术分为三个阶段
Level 0(不知道为啥从零开始)是编辑器的起始阶段,代表旧一代的编辑器的实现
Level 1 第二阶段,是在第一阶段发展过来的,有一定的先进性,也引入了主流的一些编程思想,对于富文本内容有一定的抽象
Level 2 第三阶段,完全不依赖浏览器的编辑能力,独立的实现光标和排版
下面我在介绍的编辑器的时候也会对它们所处的阶段进行简单的归纳,方便大家理解。
2008 - CKEditor 1-4

CKEditor 1-4 可以代表传统编辑器的技术路线(同类型技术的主要是 UEditor),主要依赖于浏览器原生的编辑能力,用户内容的输入是浏览器直接处理,加粗、斜体、回车等这类的处理则是捕获浏览器的事件来覆盖浏览器默认行为来实现,再辅以一些 DOM 的嵌套规则(dtd)和复杂数据输入(如粘贴)的过滤规则来约束数据的正确性,这类编辑器整体思路还是比较清晰的。
内容的可编辑主要依赖 DOM 的 contentEditable 属性,基于原生 execCommand 或者自定义扩展的 execCommand 去操作 DOM 实现富文内容的修改。
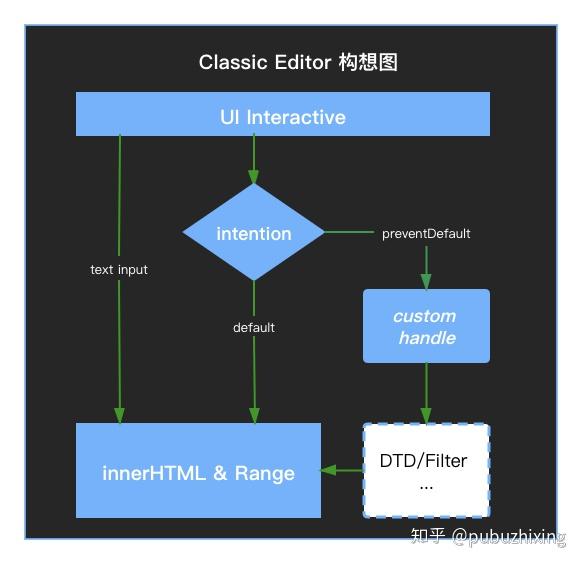
ps: 上图是根据个人理解绘制的架构构想图,跟实际可能会有些出入
- 文本输入基本上是浏览器的默认行为
- 复杂的样式或者格式操作则会进入交互判断逻辑,如果有默认行为不满足要求(比如不同浏览器之间表现不一致)的则会阻止默认行为,由开发者进行自定义的操作,也就是自主实现对 DOM 或者 Range 的更新。
特点
- 依赖浏览器原生的编辑能力(Level 0)
- 基于浏览器 execCommand 或者扩展的指令集
- 基于 DOM 的嵌套规则和过滤
- 输出富文本内容是 HTML 字符串
优点
- 基于浏览器原生编辑能力,输入非常流畅
- 没有令人头疼的 IME(组合输入)问题
缺点
- 不可以预测的交互,容易出现数据混乱(拖拽、复制粘贴、删除)
- 相同操作不同浏览器可能有不同的实现(比如基本的加粗、斜体、Enter),很难实现表现和数据完全统一
- 特定结构的富文本内容(图片 + Caption)实现复杂
- 对于协同编辑器支持困难(CKEditor 5 重头开始做的根本原因)
因为 CKEditor 4 本质还是直接操作 DOM,根据我所理解的阶段划分,我把它归为第一阶段(Level 0),其实在这之前应该还有使用 textarea 实现的编辑器,比如代码编辑器 Codemirror,它们大体上都是属于第一阶段。
2012 - Quill.js

2012 最具代表性的编辑器就是 Quill.js,它的出现给富文本编辑器带了很多新的东西,也是目前开源编辑器里面受众非常大的一款编辑器,github star 数量高达 27.7k,石墨文档背后的富文本内容编辑就是基于 Quill.js 实现的,我们的 PingCode Agile 最初在进行编辑器技术选型的时候也是选择了 Quill.js,基于 Quill.js 封装了一个 Angular 的组件。
Quill.js 底层还是依赖 DOM 的 contentEditable 特性,但是 Quill 对 DOM Tree 以及数据的修改操作进行了抽象,这意味着编辑器开发者大部分场景下其实不是直接通过修改 DOM 完成编辑器功能的,而是通过 Quill 提供的模型操作 API 来完成操作的,主角变成了:Delta、Parchment & Blots。
Delta
Quill 使用 Delta 来描述编辑器的内容及其变化,Delta 非常简洁,却极富表现力。
Delta 是 JSON 的一个子集,只包含一个 ops 属性,它的值是一个对象数组,每个数组项代表对编辑器的一个操作(以编辑器初始状态为空为基准)。
下面是一段富文本内容描述:

用 Delta 进行描述如下:
{
"ops": [
{
"insert": "Hello "
},
{
"attributes": {
"bold": true
},
"insert": "Quill"
},
{
"insert": "!"
}
]
}
Delta 只有 3 种动作和 1 种属性,却足以描述任何富文本内容和任意内容的变化。
3 种动作:
- insert:插入
- retain:保留
- delete:删除
1 种属性:
- attributes:格式属性
Delta 的一个特点是只描述内容的变化,最终的内容是由一系列的变化组成的。
对于协同编辑器有一些了解的同学看到 Delta 数据模型应该很熟悉,Delta 其实是 OT 模型的一种实现,OT 操作是做协同编辑的一种思路,所以 Quill 可以说是为协同而生的编辑器。
Parchment & Blots
Quill.js 中对于 DOM 的抽象,Parchment 其实是与 DOM 树对应的结构,Parchment 由 Blots 组成,Blot 即与 DOM 的 Node 对应,Quill.js 文档怎么渲染完全由 Blot 决定,那么这层模型其实就是 Delta 数据与最终 UI 之间的一个中间层;
对应关系:
Editor Container ⇐⇒ Parchment
DOM Node ⇐⇒ Blot
有了这层抽象的模型,最大的改变就是开发者直接操作的内容从极难约束的 DOM 变成了可以被严格约束的 Parchment & Blots,最终 DOM 的修改被限制在 Blots 中完成(当然还是操作 DOM)。
LinkBlot 示例:

Delta 中数据形态:
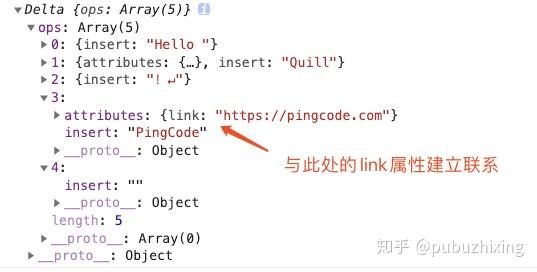
架构图
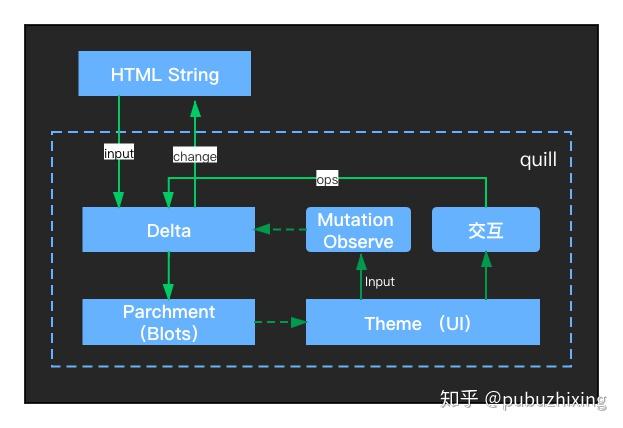
- 文本输入基本上是浏览器的默认行为,Quill.js 会监控 DOM 的变化(MutationObserver),最终把 DOM 的更改同步到 Delta 模型数据中。
- 复杂的样式或者格式操作等非浏览器默认行为,则会直接更新 Delta 模型数据,由 Delta 驱动 Parchment & Blots 的更新,然后最终才到 UI 的变化。
特点
- 依赖浏览器原生的编辑能力(Level 1)
- 数据更新主体是 Delta,DOM 的更新由单独的 Parchment & Blots 描述
- 输出数据可以是 HTML 的字符串也可以由 Delta 描述的一系列操作(也就是 JSON),但是可读性补不好一般很少作为结果数据保存
- Quill.js 主体、Parchment、Delta 都是独立的仓储,架构良好
因为引入了数据模型、抽象出了数据变化的操作,所以把 Quill.js 定义 Level 1 阶段,后面出来的编辑器多少都有借鉴 Quill.js 的实现思路。
2015 - ProseMirror

大名鼎鼎的 Confluence 就是基于 ProseMirror 开发的,所以对于 ProseMirror 的扩展能力和稳定性应该毋庸质疑,因为 ProseMirror 不同模块是分仓储的,所以我不太能准确的把握它的具体的创建时间(从社区大佬的说明看大概在 2015 年)
从实现原理上看 ProseMirror 也是依赖 contentEditable,不过非常厉害的是 ProseMirror 将主流的前端的架构理念应用到了编辑器的开发中,比如彻底使用纯 JSON 数据描述富文本内容,引入不可变数据以及 Virtual DOM 的概念,还有插件机制、分层、Schemas(范式)等等,所以感觉 ProseMirror 是一款理念先进且体系相对比较完善的一款编辑器(或者说框架)。
JSON 描述富文本内容
比如:

用 JSON 描述如下:
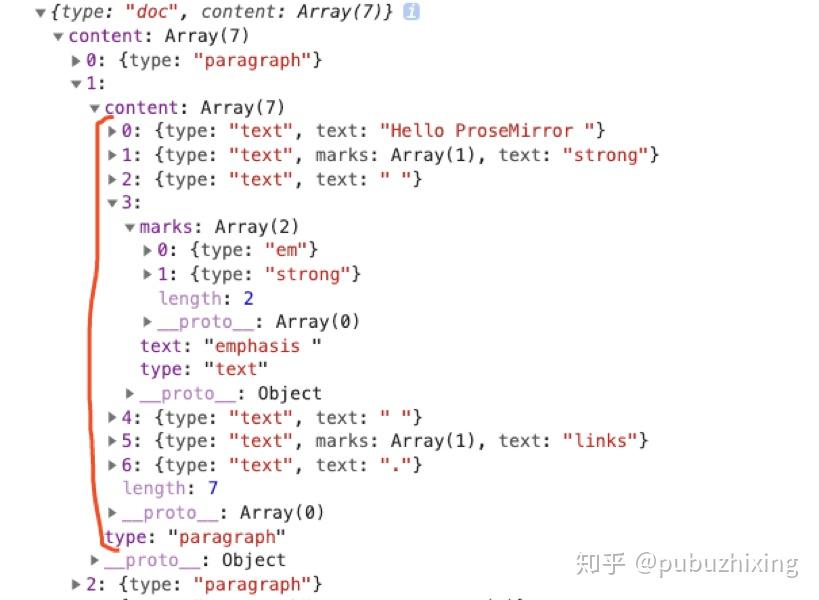
Schemas(范式)
下图是代办项功能插件的例子,使用 Spec 描述了节点具有的属性,以及如何根据属性渲染这个节点的内容:
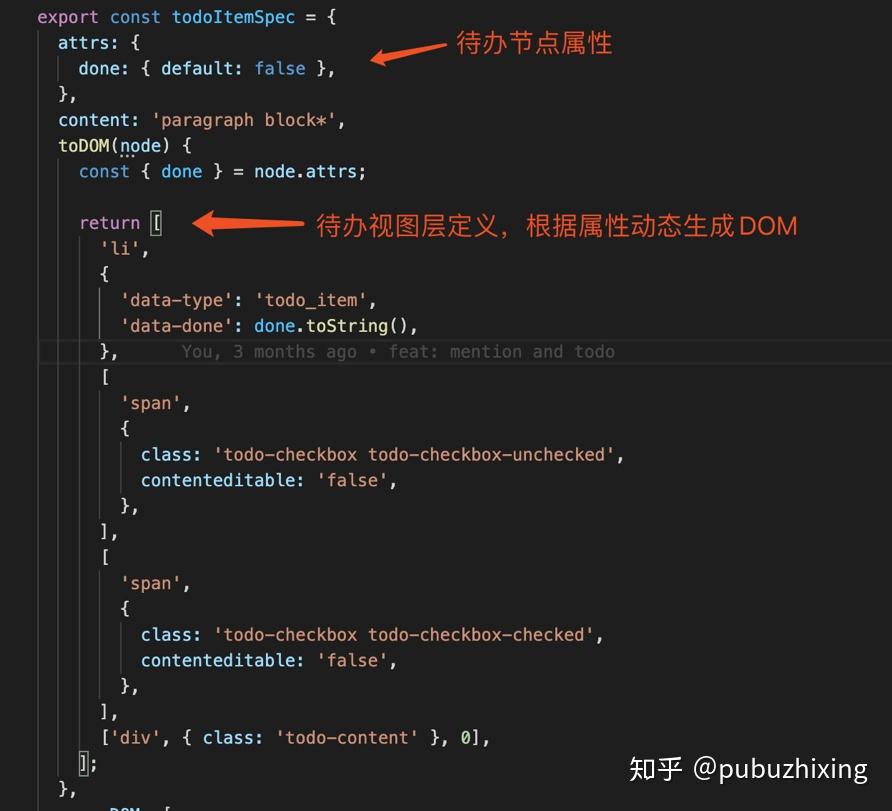
有了数据以及数据类型对应的范式的定义,从 JSON 数据到 DOM 的更改是可以完全由 ProseMirror 接管,ProseMirror 是在中间做了一层虚拟 DOM 来完成数据到 DOM 的驱动更新。
attrs:存储节点的自定义属性
content:对子元素的约束描述(正则匹配)
toDOM:根据节点数据渲染 DOM 的定义
parseDOM:提取 todo-item 的 DOM 节点属性的定义
主要想说的是 toDOM,这种写法类似于 React 使用 JSX 定义渲染 DOM 的指令,但是感觉它应该没有 JSX 强大。
Transform
ProseMirror 有一个单独的模块来定义和实现文档的修改,这样内容的修改被统一起来,并且最终都会转化为底层的原子操作(为协同编辑提供可能),而且可以在任何插件中做拦截处理,比如实现:记录数据更改操作来实现撤销和重做等。
到 ProseMirror 这里可以有一张状态图:
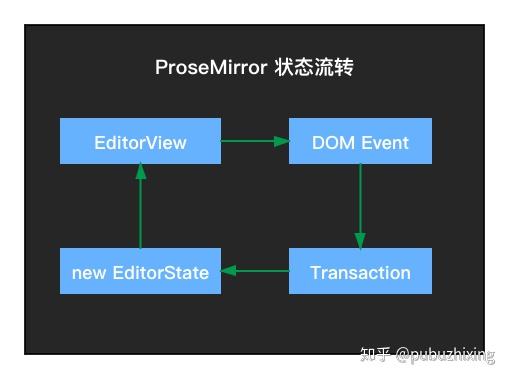
到这里前端同学看起来应该很熟悉了:
- 引入不可变数据的概念,统一了内容的修改,把原来的更改 DOM 的方式改为对不可变数据的修改
- 和 React 类似的方式实现了单向数据驱动,所以编辑器整个的数据处理有了一个完整的数据流,稳定切可控。
特点
- 依赖浏览器原生的编辑能力(Level 1)
- 嵌套的文档模型(区别于 Delta 的 OT 模型,它的文档模型是通常意义上的 JS 对象模型,对应的模型数据可以作为结果直接存储)
- Schemas(范式)约定模型嵌套以及渲染规则
- 统一数据更新流,采用单向数据流、不可变数据及虚拟 DOM 避免直接操作 DOM(这一点确实融合了主流的函数式编程的思想)
- 输出的数据是纯 JSON
- 个人认为唯一不足的就是它需要开发者重新学习它独有的描述 DOM 的范式(相对于 Slate)
ProseMirror 是 CodeMirror 作者的另一力作,理念应该说非常新了,而且实现上它代理了浏览器大部分的默认行为,把操作转换为数据的变换,进而更新 UI,可以说是当之无愧的 Level 1 阶段。
2015 - Draft.js

Draft.js 是第一个把富文本编辑器与 React 结合的开源作品,开发者在进行编辑器开发时既不用操作 DOM、也不用单独学习一套构建 UI 的范式,而是可以直接编写 React 组件实现编辑器的 UI,某种意义上是生产力的巨大提升,因为 Draft.js 和 React 一样也是 Facebook 团队开源的框架,所以 Draft.js 整体理念与 React 非常的吻合,也代表了主流的编程思想,比如使用状态管理保存富文本数据、使用 Immutable.js 库、数据的修改基本全部代理了浏览器的默认行为,通过状态管理的方式修改富文本数据。
知乎的富文本编辑器就是用 draft.js 实现的
当然它也有一定的局限性,因为它只为使用 React 框架富文本编辑器服务,其它框架想使用它应该非常难。
Draft 的大概情况
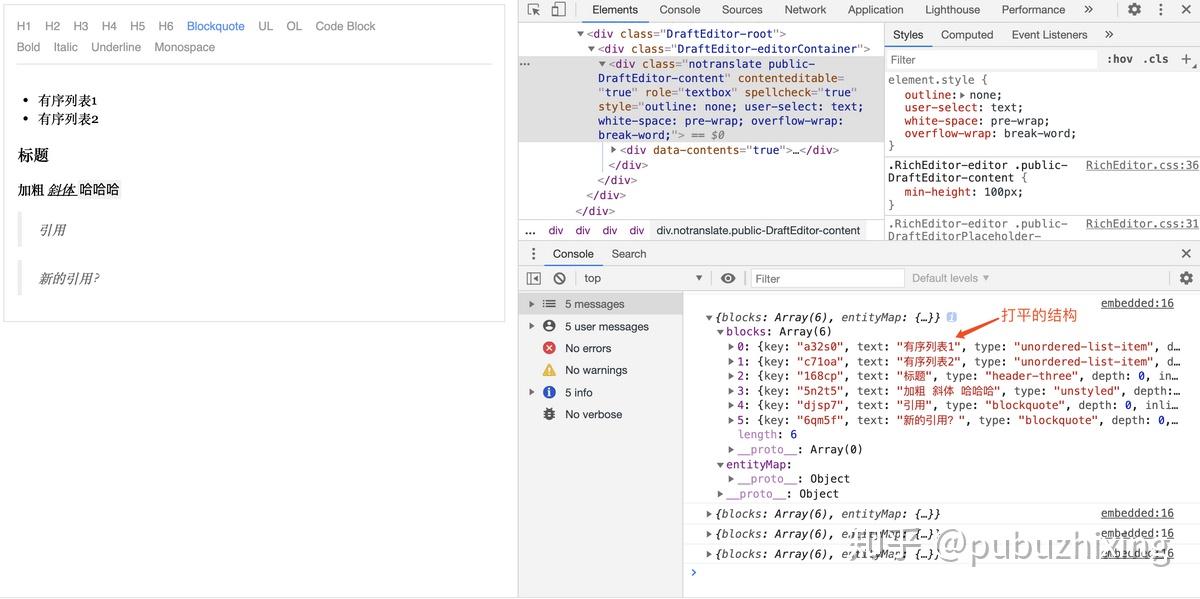
我打开 Demo 试了下,发现即使这种引用或者列表它也使用打平的数据结构来实现,通过 type 来区分 block 类型;
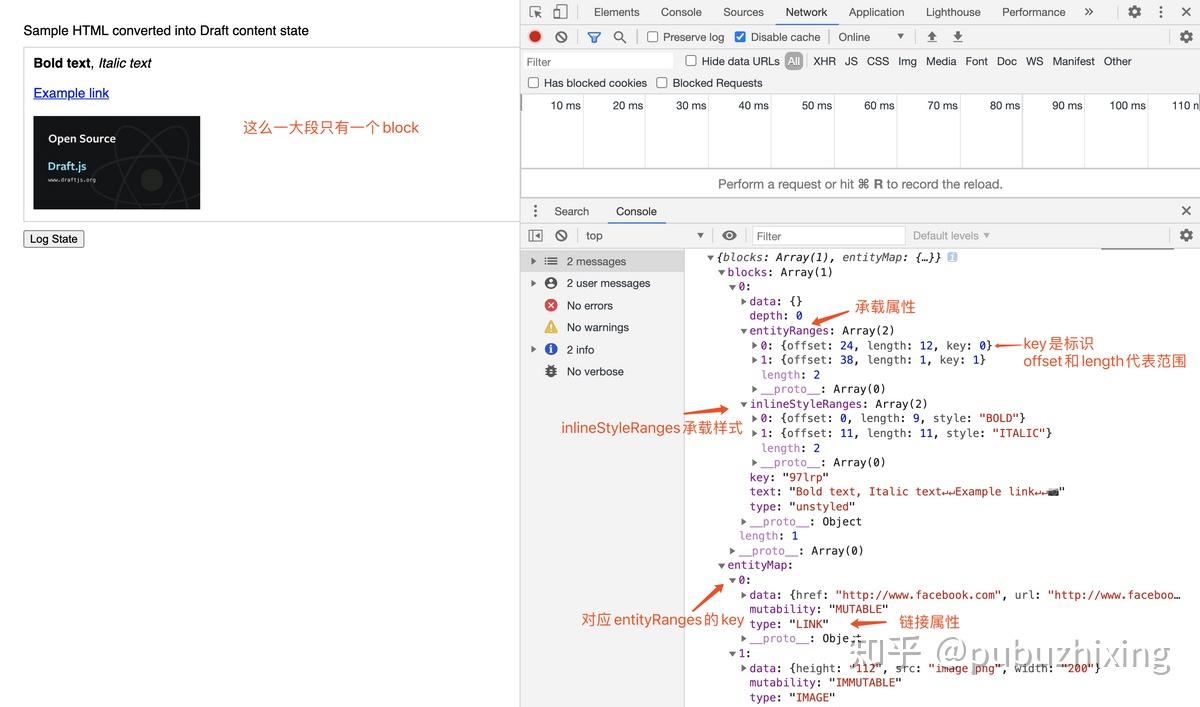
可以看出 draft.js 虽然也抽象了基于 JSON 的数据模型,但是它对于嵌套数据的支持是有些弱的,这也是它的硬伤。
特点
- 依赖浏览器原生的编辑能力(Level 1 Pro)
- React 作为 UI 层
- 与 React 结合的富文本数据的管理(状态管理)
- 毋容置疑 Draft.js 因为没有做伤筋动骨的架构更新,它的稳定性、细节处理应该相较于其它框架(Slate)有很大优势
- Draft 对于文档数据的描述过于死板,比如需要嵌套节点的表格就不那么容易实现,即使能把一个表格当做富文组件嵌到 Draft 编辑器中,它的局限性也很大(比如单元格中基本的加粗、斜体、链接就没办法借助编辑器的能力实现了),所以它的数据模型是不太完善的。
因为 Draft.js 直接把富文本编辑器开发与 React 集成,开发者拓展编辑器功能其实相当于写 React 组件,这是一个巨大的提升,并且完全使用状态管理的思想管理富文本数据,技术上已经有相当大的进步,所以把它定义为第二阶段的加强版(Level 1 Pro)。
2016 - Slate

Slate 可以说是世界上最牛逼的编辑器框架(个人见解),相较于前面介绍的一系列编辑器它的出场是最晚的,但也因此它汲取了其它编辑器的一些经验,并且由于作者有极致的追求,Slate 的架构也在不断的重构升级,目前仍然处在 beta 版本,最新版本是 0.58.x。
Slate 从一出来大量借鉴了 Quill、ProseMirror、Draft.js 的优点,虽然是主流编辑器中出道比较晚的,但是由于结构良好,理念新颖,还有作者对于架构的持续改进,目前还是比较受欢迎的一款编辑器。
架构图
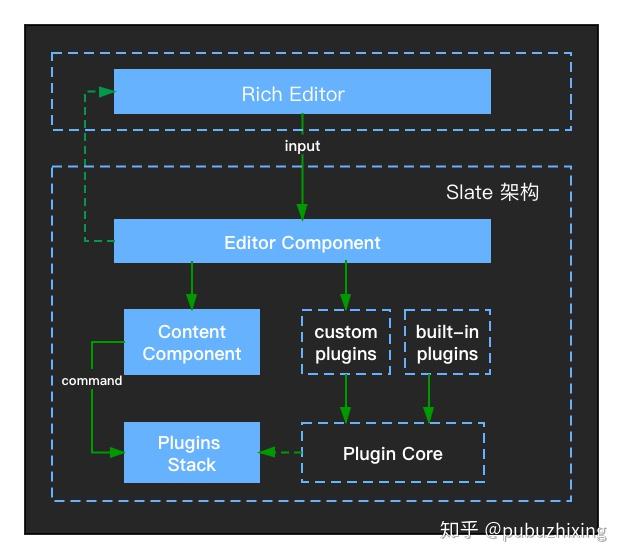
可以看出 Slate 是可以称为编辑器框架的,它不提供开箱即用的功能,只提供开发编辑器的基础架构,如果想实现一款编辑器需要基于这套架构实现一系列的编辑功能的插件。
特点
- 依赖浏览器原生的编辑能力(Level 1 Pro)
- Shchema 定义数据的约束规则(ProseMirror)
- Nest Data Model(ProseMirror)
- React 作为视图层(Draft.js)
- 插件作为一等公民,开发者对于交互拥有很大的控制权(Draft.js)
- Immutable、统一的数据更改 Commands(Draft.js)
这个时期的 Slate 有的更多是其它编辑器的影子,集众家之长。
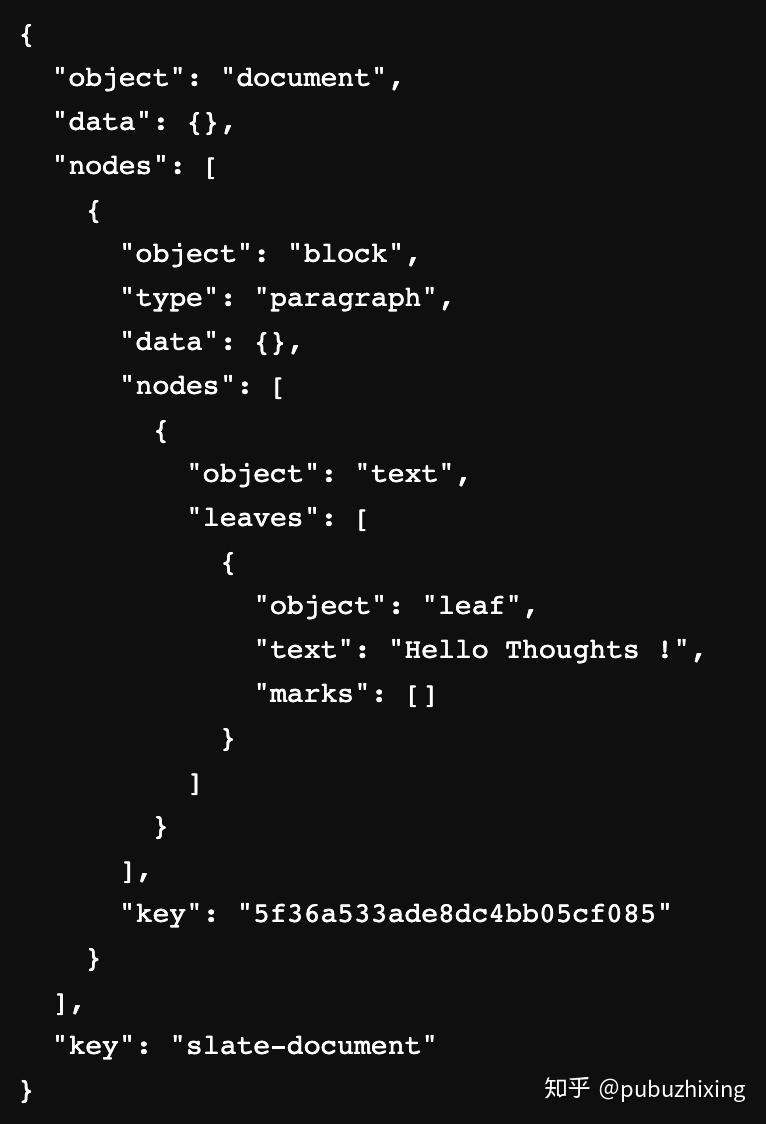
可以看下最初的 Slate 数据:
2018 - Slate Core
- 抽取独立的视图层,底层不在强依赖 React
这让 Angular、Vue 框架使用 Slate 框架成为可能,不过这也有一定的门槛,因为需要重新实现一个视图层
Slate 的 Issue 中就有提到,目前以及以后的很长时间官方都不会提供 Angular 的视图层。
这时候的 Slate 数据:

相较于最初结构上了有了一些优化。
架构图
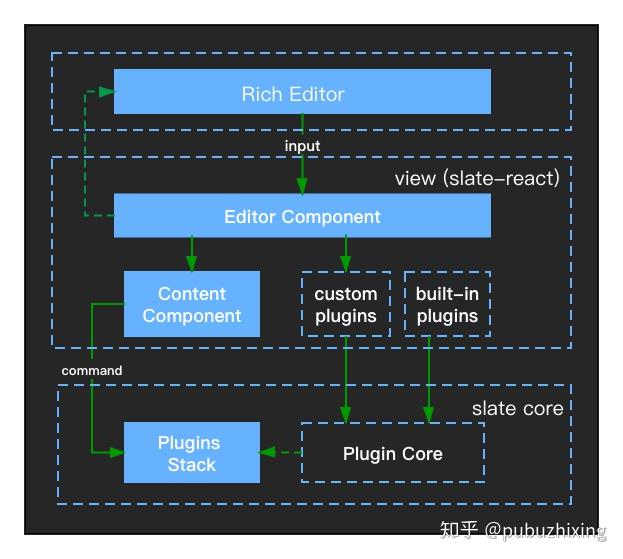
我们的 PingCode Wiki 产品第一版的编辑器就是基于上面的这套架构的基础上开发(得益于 Slate 抽离出独立的视图层,让底层不再依赖 React)的,因为 Slate 官方并不提供基于 Angular 的视图层,所有我们自己开发了基于 Angular 的视图层(ngx-slate)。
2019 - Slate Migration
2019 年年底的时候,Slate 对于它自己进行了一次大的架构升级,这次被称为大修的升级(0.50.x)可以说亮点非常多,首先是 TypeScript 对所有代码重新实现,其次是把原来复杂的插件机制简化,还有把不可变数据的模型改为更简洁对新手更友好的 Immer,同样是视图层与核心实现分离,虽然目前还有不少缺陷,包括中文输入以及浏览器兼容性的问题,但是通过实践发现这些都可以在视图层进行修复的。
架构图
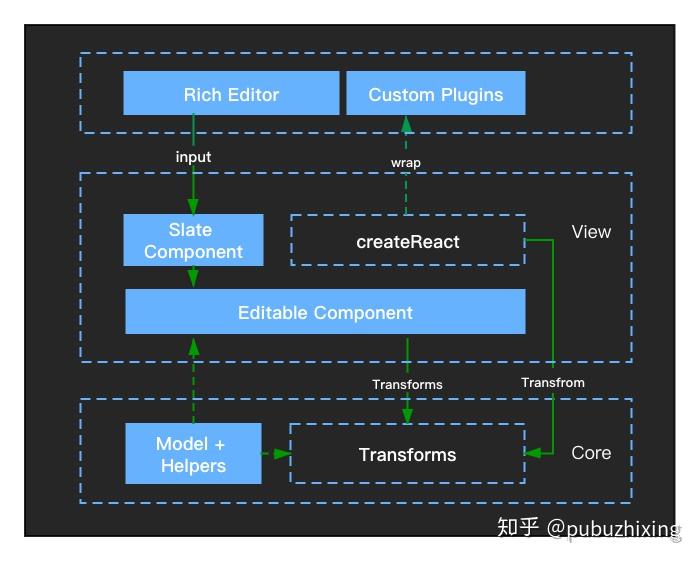
特点
- 非常简洁的数据模型
- 设计出了一套抽象度非常高的编辑器业务 Hook,业务方可以进行重写和拓展,可以作为插件的替代品,它非常易于理解和调试
- 使用 Immer 作为不可变数据模型
- 编码思路采用纯函数 + 接口的方式,思路和代码都非常之简洁
最新版 Slate 的数据:

Slate 虽然集大家之所长并且在不断的推进架构的升级,但它仍然要依赖浏览器的可编辑能力,也要为如何同步 Slate 行为与浏览器默认行为做很多小心的处理,中文输入处理依然是一个头疼的事情,所以它本质上还是第二阶段的加强版(Level 1 Pro)。
ps:我们基于最新版本 Slate 重新打造的基于 Angular 的编辑器很快就要对外上线了,从整体的稳定性以及编辑能力都已经超越了旧版编辑器,所以新版 Slate 即使对架构进行完全的重构,它的底层依然是比较稳健的(有测试覆盖),大部分的问题包括中文输入法以及浏览器的兼容性都可以在视图层很容易的解决掉。
编辑器的未来
其实未来早已来临,早在 2010 年 Google Doc 就使用了全新的技术来实现富文本编辑器,就是大家通常说的第三阶段(Level 2),可以实现文本的独立排版,不再依靠浏览器的任何编辑功能,自主实现选区光标和内容排版,只不过目前还没有一款基于这套架构的开源技术。
总结
得益于开源技术,编辑器的实践经验得以延续和发展,没有绝对的好坏,每一款编辑器都有自己的特点,CKEditor 是发展时间最久,它的技术线路清晰可寻,发展时间最长,跨越了编辑器技术的第一阶段和第二阶段,从 CKEditor 4 到 CKEditor 5 更是经历完全的重构,从根本上解决协同编辑的问题,Quill.js 也可以称为老牌的编辑器了,受众非常大,从市面使用 Quill.js 的产品(石墨文档、ClickUp)也可以看出它的可塑性非常强,ProseMirror 可以说是非常稳定的编辑器,知乎上也有人专门拿它和 Slate 做过对比,况且有 Confluence 做背书自然差不了,最晚出来的 Slate,则一路大刀阔斧的重构,目前整体架构异常优雅和简洁,又搭载了 TypeScript,感觉势头非常强劲,都是非常值得学习的。
最后用一张时间线的图重新回顾下开源富文本编辑器的历史