003 - 编译与解释原理
学习目标
通过本章学习,您将能够:
- 深入理解编译和解释的基本概念和工作原理
- 掌握编译器和解释器的内部结构和执行流程
- 比较编译型和解释型语言的优缺点和适用场景
- 了解现代混合执行模式(JIT 编译、字节码等)
- 理解程序执行的不同阶段和性能影响因素
- 掌握编译优化和解释优化的基本技术
3.1 编译与解释概述
3.1.1 基本概念
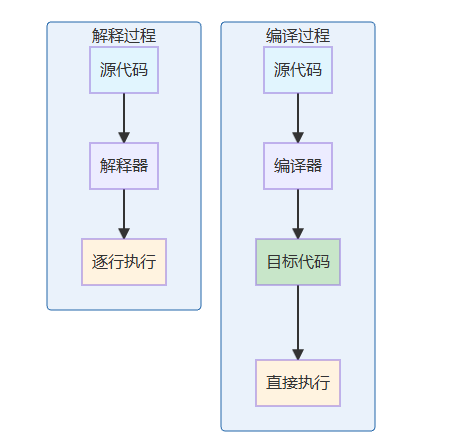
编译(Compilation):将高级语言源代码一次性转换为目标机器代码的过程。
解释(Interpretation):逐行读取和执行高级语言源代码的过程。
3.1.2 历史发展
timeline
title 编译与解释技术发展历程
1950s : 第一代编译器
: FORTRAN编译器
: 汇编器发展
1960s : 编译理论奠基
: 上下文无关文法
: LR解析算法
1970s : 解释器兴起
: BASIC解释器
: 交互式编程
1980s : 优化编译器
: 代码优化技术
: RISC架构支持
1990s : 虚拟机技术
: Java虚拟机
: 字节码解释
2000s : JIT编译
: 即时编译技术
: 动态优化
2010s : 现代编译器
: LLVM框架
: 跨平台编译
3.2 编译原理详解
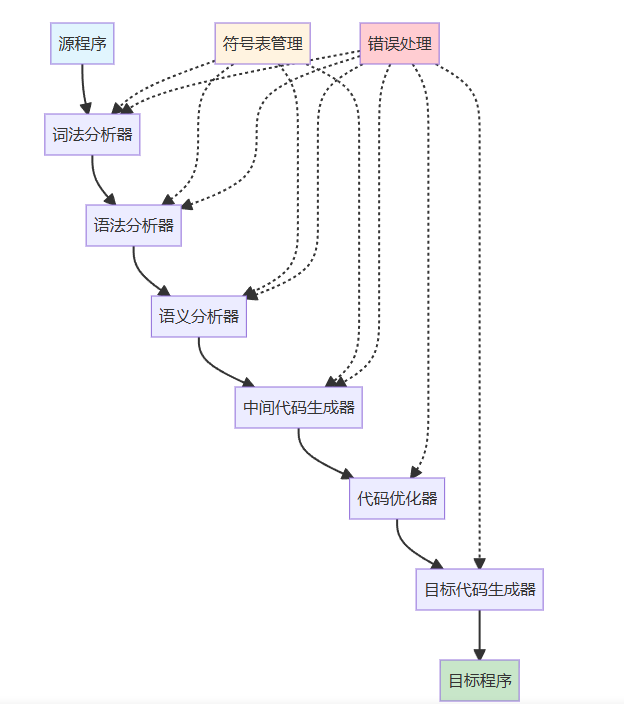
3.2.1 编译器结构
3.2.2 编译过程详解
前端处理(Front-end)
1. 词法分析(Lexical Analysis)
# 词法分析器示例(Python实现)
import re
from enum import Enum
from dataclasses import dataclass
from typing import List, Iterator
class TokenType(Enum):
# 关键字
IF = 'IF'
ELSE = 'ELSE'
WHILE = 'WHILE'
FOR = 'FOR'
INT = 'INT'
FLOAT = 'FLOAT'
# 标识符和字面量
IDENTIFIER = 'IDENTIFIER'
NUMBER = 'NUMBER'
STRING = 'STRING'
# 运算符
PLUS = 'PLUS'
MINUS = 'MINUS'
MULTIPLY = 'MULTIPLY'
DIVIDE = 'DIVIDE'
ASSIGN = 'ASSIGN'
# 比较运算符
EQUAL = 'EQUAL'
NOT_EQUAL = 'NOT_EQUAL'
LESS_THAN = 'LESS_THAN'
GREATER_THAN = 'GREATER_THAN'
# 分隔符
SEMICOLON = 'SEMICOLON'
COMMA = 'COMMA'
LEFT_PAREN = 'LEFT_PAREN'
RIGHT_PAREN = 'RIGHT_PAREN'
LEFT_BRACE = 'LEFT_BRACE'
RIGHT_BRACE = 'RIGHT_BRACE'
# 特殊
EOF = 'EOF'
NEWLINE = 'NEWLINE'
WHITESPACE = 'WHITESPACE'
@dataclass
class Token:
type: TokenType
value: str
line: int
column: int
class Lexer:
def __init__(self, source_code: str):
self.source = source_code
self.position = 0
self.line = 1
self.column = 1
# 关键字映射
self.keywords = {
'if': TokenType.IF,
'else': TokenType.ELSE,
'while': TokenType.WHILE,
'for': TokenType.FOR,
'int': TokenType.INT,
'float': TokenType.FLOAT,
}
# 运算符映射
self.operators = {
'+': TokenType.PLUS,
'-': TokenType.MINUS,
'*': TokenType.MULTIPLY,
'/': TokenType.DIVIDE,
'=': TokenType.ASSIGN,
'==': TokenType.EQUAL,
'!=': TokenType.NOT_EQUAL,
'<': TokenType.LESS_THAN,
'>': TokenType.GREATER_THAN,
}
# 分隔符映射
self.delimiters = {
';': TokenType.SEMICOLON,
',': TokenType.COMMA,
'(': TokenType.LEFT_PAREN,
')': TokenType.RIGHT_PAREN,
'{': TokenType.LEFT_BRACE,
'}': TokenType.RIGHT_BRACE,
}
def current_char(self) -> str:
"""获取当前字符"""
if self.position >= len(self.source):
return '\0' # EOF
return self.source[self.position]
def peek_char(self, offset: int = 1) -> str:
"""预览后续字符"""
peek_pos = self.position + offset
if peek_pos >= len(self.source):
return '\0'
return self.source[peek_pos]
def advance(self) -> str:
"""移动到下一个字符"""
char = self.current_char()
self.position += 1
if char == '\n':
self.line += 1
self.column = 1
else:
self.column += 1
return char
def skip_whitespace(self):
"""跳过空白字符"""
while self.current_char().isspace() and self.current_char() != '\n':
self.advance()
def read_number(self) -> Token:
"""读取数字"""
start_line, start_column = self.line, self.column
number_str = ''
# 读取整数部分
while self.current_char().isdigit():
number_str += self.advance()
# 检查小数点
if self.current_char() == '.' and self.peek_char().isdigit():
number_str += self.advance() # 添加小数点
while self.current_char().isdigit():
number_str += self.advance()
return Token(TokenType.NUMBER, number_str, start_line, start_column)
def read_identifier(self) -> Token:
"""读取标识符或关键字"""
start_line, start_column = self.line, self.column
identifier = ''
# 读取标识符
while (self.current_char().isalnum() or self.current_char() == '_'):
identifier += self.advance()
# 检查是否为关键字
token_type = self.keywords.get(identifier, TokenType.IDENTIFIER)
return Token(token_type, identifier, start_line, start_column)
def read_string(self) -> Token:
"""读取字符串字面量"""
start_line, start_column = self.line, self.column
quote_char = self.advance() # 跳过开始引号
string_value = ''
while self.current_char() != quote_char and self.current_char() != '\0':
if self.current_char() == '\\':
self.advance() # 跳过转义字符
escape_char = self.advance()
# 处理转义序列
if escape_char == 'n':
string_value += '\n'
elif escape_char == 't':
string_value += '\t'
elif escape_char == 'r':
string_value += '\r'
elif escape_char == '\\':
string_value += '\\'
elif escape_char == quote_char:
string_value += quote_char
else:
string_value += escape_char
else:
string_value += self.advance()
if self.current_char() == quote_char:
self.advance() # 跳过结束引号
else:
raise SyntaxError(f"未终止的字符串,行 {start_line},列 {start_column}")
return Token(TokenType.STRING, string_value, start_line, start_column)
def tokenize(self) -> List[Token]:
"""将源代码转换为token列表"""
tokens = []
while self.position < len(self.source):
self.skip_whitespace()
if self.current_char() == '\0':
break
char = self.current_char()
start_line, start_column = self.line, self.column
# 处理换行
if char == '\n':
tokens.append(Token(TokenType.NEWLINE, char, start_line, start_column))
self.advance()
# 处理数字
elif char.isdigit():
tokens.append(self.read_number())
# 处理标识符和关键字
elif char.isalpha() or char == '_':
tokens.append(self.read_identifier())
# 处理字符串
elif char in ['"', "'"]:
tokens.append(self.read_string())
# 处理双字符运算符
elif char + self.peek_char() in self.operators:
operator = char + self.peek_char()
tokens.append(Token(self.operators[operator], operator, start_line, start_column))
self.advance()
self.advance()
# 处理单字符运算符
elif char in self.operators:
tokens.append(Token(self.operators[char], char, start_line, start_column))
self.advance()
# 处理分隔符
elif char in self.delimiters:
tokens.append(Token(self.delimiters[char], char, start_line, start_column))
self.advance()
# 处理注释
elif char == '/' and self.peek_char() == '/':
# 单行注释,跳过到行尾
while self.current_char() != '\n' and self.current_char() != '\0':
self.advance()
elif char == '/' and self.peek_char() == '*':
# 多行注释
self.advance() # 跳过 '/'
self.advance() # 跳过 '*'
while True:
if self.current_char() == '*' and self.peek_char() == '/':
self.advance() # 跳过 '*'
self.advance() # 跳过 '/'
break
elif self.current_char() == '\0':
raise SyntaxError(f"未终止的注释,行 {start_line},列 {start_column}")
else:
self.advance()
# 未知字符
else:
raise SyntaxError(f"未知字符 '{char}',行 {start_line},列 {start_column}")
# 添加EOF标记
tokens.append(Token(TokenType.EOF, '', self.line, self.column))
return tokens
# 使用示例
def demo_lexer():
source_code = """
int main() {
int x = 10;
float y = 3.14;
if (x > 5) {
printf("Hello, World!");
}
return 0;
}
"""
lexer = Lexer(source_code)
tokens = lexer.tokenize()
print("=== 词法分析结果 ===")
for token in tokens:
if token.type != TokenType.NEWLINE: # 跳过换行符以简化输出
print(f"{token.type.value:15} | {token.value:10} | 行{token.line:2}列{token.column:2}")
if __name__ == "__main__":
demo_lexer()
2. 语法分析(Syntax Analysis)
# 递归下降语法分析器示例
from typing import Optional, List
from abc import ABC, abstractmethod
# 抽象语法树节点定义
class ASTNode(ABC):
pass
class Expression(ASTNode):
pass
class Statement(ASTNode):
pass
@dataclass
class NumberLiteral(Expression):
value: float
@dataclass
class Identifier(Expression):
name: str
@dataclass
class BinaryOperation(Expression):
left: Expression
operator: str
right: Expression
@dataclass
class Assignment(Statement):
target: Identifier
value: Expression
@dataclass
class IfStatement(Statement):
condition: Expression
then_branch: List[Statement]
else_branch: Optional[List[Statement]] = None
@dataclass
class WhileStatement(Statement):
condition: Expression
body: List[Statement]
@dataclass
class Block(Statement):
statements: List[Statement]
class Parser:
def __init__(self, tokens: List[Token]):
self.tokens = tokens
self.current = 0
def current_token(self) -> Token:
"""获取当前token"""
if self.current >= len(self.tokens):
return self.tokens[-1] # EOF token
return self.tokens[self.current]
def peek_token(self, offset: int = 1) -> Token:
"""预览后续token"""
peek_pos = self.current + offset
if peek_pos >= len(self.tokens):
return self.tokens[-1] # EOF token
return self.tokens[peek_pos]
def advance(self) -> Token:
"""移动到下一个token"""
token = self.current_token()
if self.current < len(self.tokens) - 1:
self.current += 1
return token
def match(self, *token_types: TokenType) -> bool:
"""检查当前token是否匹配指定类型"""
return self.current_token().type in token_types
def consume(self, token_type: TokenType, error_message: str = "") -> Token:
"""消费指定类型的token"""
if self.current_token().type == token_type:
return self.advance()
else:
current = self.current_token()
raise SyntaxError(f"{error_message or f'期望 {token_type.value}'} "
f"但得到 {current.type.value},行 {current.line},列 {current.column}")
def parse_primary(self) -> Expression:
"""解析基本表达式"""
token = self.current_token()
if token.type == TokenType.NUMBER:
self.advance()
return NumberLiteral(float(token.value))
elif token.type == TokenType.IDENTIFIER:
self.advance()
return Identifier(token.value)
elif token.type == TokenType.LEFT_PAREN:
self.advance() # 消费 '('
expr = self.parse_expression()
self.consume(TokenType.RIGHT_PAREN, "期望 ')'")
return expr
else:
raise SyntaxError(f"意外的token {token.type.value},行 {token.line},列 {token.column}")
def parse_unary(self) -> Expression:
"""解析一元表达式"""
if self.match(TokenType.MINUS, TokenType.PLUS):
operator = self.advance().value
expr = self.parse_unary()
return BinaryOperation(NumberLiteral(0), operator, expr)
return self.parse_primary()
def parse_factor(self) -> Expression:
"""解析乘除表达式"""
expr = self.parse_unary()
while self.match(TokenType.MULTIPLY, TokenType.DIVIDE):
operator = self.advance().value
right = self.parse_unary()
expr = BinaryOperation(expr, operator, right)
return expr
def parse_term(self) -> Expression:
"""解析加减表达式"""
expr = self.parse_factor()
while self.match(TokenType.PLUS, TokenType.MINUS):
operator = self.advance().value
right = self.parse_factor()
expr = BinaryOperation(expr, operator, right)
return expr
def parse_comparison(self) -> Expression:
"""解析比较表达式"""
expr = self.parse_term()
while self.match(TokenType.LESS_THAN, TokenType.GREATER_THAN,
TokenType.EQUAL, TokenType.NOT_EQUAL):
operator = self.advance().value
right = self.parse_term()
expr = BinaryOperation(expr, operator, right)
return expr
def parse_expression(self) -> Expression:
"""解析表达式"""
return self.parse_comparison()
def parse_assignment(self) -> Statement:
"""解析赋值语句"""
if (self.current_token().type == TokenType.IDENTIFIER and
self.peek_token().type == TokenType.ASSIGN):
target = Identifier(self.advance().value)
self.consume(TokenType.ASSIGN)
value = self.parse_expression()
self.consume(TokenType.SEMICOLON, "期望 ';'")
return Assignment(target, value)
# 如果不是赋值,则作为表达式语句处理
expr = self.parse_expression()
self.consume(TokenType.SEMICOLON, "期望 ';'")
return expr
def parse_if_statement(self) -> IfStatement:
"""解析if语句"""
self.consume(TokenType.IF)
self.consume(TokenType.LEFT_PAREN, "期望 '('")
condition = self.parse_expression()
self.consume(TokenType.RIGHT_PAREN, "期望 ')'")
then_branch = self.parse_block()
else_branch = None
if self.match(TokenType.ELSE):
self.advance()
else_branch = self.parse_block()
return IfStatement(condition, then_branch, else_branch)
def parse_while_statement(self) -> WhileStatement:
"""解析while语句"""
self.consume(TokenType.WHILE)
self.consume(TokenType.LEFT_PAREN, "期望 '('")
condition = self.parse_expression()
self.consume(TokenType.RIGHT_PAREN, "期望 ')'")
body = self.parse_block()
return WhileStatement(condition, body)
def parse_block(self) -> List[Statement]:
"""解析代码块"""
statements = []
self.consume(TokenType.LEFT_BRACE, "期望 '{'")
while not self.match(TokenType.RIGHT_BRACE, TokenType.EOF):
# 跳过换行符
if self.match(TokenType.NEWLINE):
self.advance()
continue
stmt = self.parse_statement()
statements.append(stmt)
self.consume(TokenType.RIGHT_BRACE, "期望 '}'")
return statements
def parse_statement(self) -> Statement:
"""解析语句"""
# 跳过换行符
while self.match(TokenType.NEWLINE):
self.advance()
if self.match(TokenType.IF):
return self.parse_if_statement()
elif self.match(TokenType.WHILE):
return self.parse_while_statement()
elif self.match(TokenType.LEFT_BRACE):
statements = self.parse_block()
return Block(statements)
else:
return self.parse_assignment()
def parse(self) -> List[Statement]:
"""解析程序"""
statements = []
while not self.match(TokenType.EOF):
# 跳过换行符
if self.match(TokenType.NEWLINE):
self.advance()
continue
stmt = self.parse_statement()
statements.append(stmt)
return statements
# AST可视化
class ASTVisualizer:
def __init__(self):
self.indent_level = 0
def indent(self) -> str:
return " " * self.indent_level
def visit(self, node: ASTNode) -> str:
method_name = f"visit_{type(node).__name__}"
method = getattr(self, method_name, self.generic_visit)
return method(node)
def generic_visit(self, node: ASTNode) -> str:
return f"{self.indent()}{type(node).__name__}"
def visit_NumberLiteral(self, node: NumberLiteral) -> str:
return f"{self.indent()}NumberLiteral({node.value})"
def visit_Identifier(self, node: Identifier) -> str:
return f"{self.indent()}Identifier({node.name})"
def visit_BinaryOperation(self, node: BinaryOperation) -> str:
result = f"{self.indent()}BinaryOperation({node.operator})\n"
self.indent_level += 1
result += self.visit(node.left) + "\n"
result += self.visit(node.right)
self.indent_level -= 1
return result
def visit_Assignment(self, node: Assignment) -> str:
result = f"{self.indent()}Assignment\n"
self.indent_level += 1
result += self.visit(node.target) + "\n"
result += self.visit(node.value)
self.indent_level -= 1
return result
def visit_IfStatement(self, node: IfStatement) -> str:
result = f"{self.indent()}IfStatement\n"
self.indent_level += 1
result += f"{self.indent()}Condition:\n"
self.indent_level += 1
result += self.visit(node.condition) + "\n"
self.indent_level -= 1
result += f"{self.indent()}ThenBranch:\n"
self.indent_level += 1
for stmt in node.then_branch:
result += self.visit(stmt) + "\n"
self.indent_level -= 1
if node.else_branch:
result += f"{self.indent()}ElseBranch:\n"
self.indent_level += 1
for stmt in node.else_branch:
result += self.visit(stmt) + "\n"
self.indent_level -= 1
self.indent_level -= 1
return result.rstrip()
def visit_Block(self, node: Block) -> str:
result = f"{self.indent()}Block\n"
self.indent_level += 1
for stmt in node.statements:
result += self.visit(stmt) + "\n"
self.indent_level -= 1
return result.rstrip()
# 使用示例
def demo_parser():
source_code = """
x = 10;
y = x + 5 * 2;
if (y > 15) {
z = y - 10;
}
"""
print("=== 源代码 ===")
print(source_code)
# 词法分析
lexer = Lexer(source_code)
tokens = lexer.tokenize()
# 语法分析
parser = Parser(tokens)
ast = parser.parse()
# 可视化AST
visualizer = ASTVisualizer()
print("\n=== 抽象语法树 ===")
for stmt in ast:
print(visualizer.visit(stmt))
print()
if __name__ == "__main__":
demo_parser()
后端处理(Back-end)
3. 代码生成(Code Generation)
# 简单的代码生成器示例
class CodeGenerator:
def __init__(self):
self.code = []
self.label_counter = 0
self.temp_counter = 0
def new_label(self) -> str:
"""生成新标签"""
label = f"L{self.label_counter}"
self.label_counter += 1
return label
def new_temp(self) -> str:
"""生成新临时变量"""
temp = f"t{self.temp_counter}"
self.temp_counter += 1
return temp
def emit(self, instruction: str):
"""生成指令"""
self.code.append(instruction)
def generate(self, node: ASTNode) -> str:
"""生成代码"""
method_name = f"generate_{type(node).__name__}"
method = getattr(self, method_name, self.generic_generate)
return method(node)
def generic_generate(self, node: ASTNode) -> str:
raise NotImplementedError(f"代码生成未实现: {type(node).__name__}")
def generate_NumberLiteral(self, node: NumberLiteral) -> str:
"""生成数字字面量代码"""
temp = self.new_temp()
self.emit(f"{temp} = {node.value}")
return temp
def generate_Identifier(self, node: Identifier) -> str:
"""生成标识符代码"""
return node.name
def generate_BinaryOperation(self, node: BinaryOperation) -> str:
"""生成二元运算代码"""
left_result = self.generate(node.left)
right_result = self.generate(node.right)
temp = self.new_temp()
self.emit(f"{temp} = {left_result} {node.operator} {right_result}")
return temp
def generate_Assignment(self, node: Assignment) -> str:
"""生成赋值语句代码"""
value_result = self.generate(node.value)
target_name = self.generate(node.target)
self.emit(f"{target_name} = {value_result}")
return target_name
def generate_IfStatement(self, node: IfStatement) -> str:
"""生成if语句代码"""
condition_result = self.generate(node.condition)
else_label = self.new_label()
end_label = self.new_label()
# 条件跳转
self.emit(f"if not {condition_result} goto {else_label}")
# then分支
for stmt in node.then_branch:
self.generate(stmt)
if node.else_branch:
self.emit(f"goto {end_label}")
self.emit(f"{else_label}:")
# else分支
for stmt in node.else_branch:
self.generate(stmt)
self.emit(f"{end_label}:")
else:
self.emit(f"{else_label}:")
return ""
def get_code(self) -> List[str]:
"""获取生成的代码"""
return self.code
# 使用示例
def demo_code_generation():
source_code = """
x = 10;
y = x + 5 * 2;
if (y > 15) {
z = y - 10;
}
"""
print("=== 源代码 ===")
print(source_code)
# 词法分析
lexer = Lexer(source_code)
tokens = lexer.tokenize()
# 语法分析
parser = Parser(tokens)
ast = parser.parse()
# 代码生成
generator = CodeGenerator()
for stmt in ast:
generator.generate(stmt)
print("\n=== 生成的中间代码 ===")
for i, instruction in enumerate(generator.get_code(), 1):
print(f"{i:2d}: {instruction}")
if __name__ == "__main__":
demo_code_generation()
3.2.3 编译优化技术
mindmap
root((编译优化))
局部优化
常量折叠
死代码消除
强度削减
公共子表达式消除
全局优化
数据流分析
活跃变量分析
到达定义分析
循环优化
过程间优化
内联展开
过程间常量传播
全程序分析
目标相关优化
指令调度
寄存器分配
流水线优化
3.3 解释原理详解
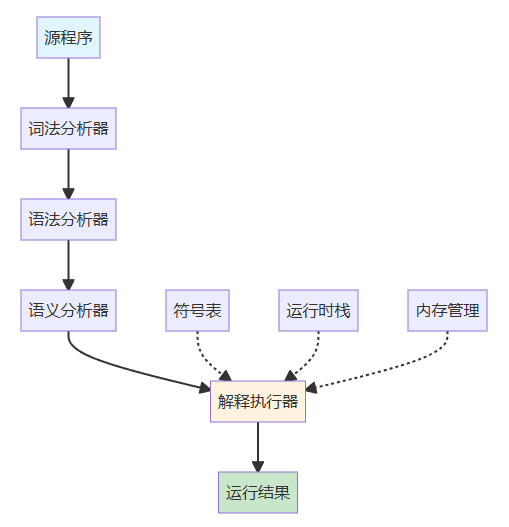
3.3.1 解释器结构
3.3.2 解释器实现
# 树遍历解释器实现
from typing import Dict, Any, List
import operator
class Environment:
"""环境:变量作用域管理"""
def __init__(self, parent=None):
self.parent = parent
self.variables: Dict[str, Any] = {}
def define(self, name: str, value: Any):
"""定义变量"""
self.variables[name] = value
def get(self, name: str) -> Any:
"""获取变量值"""
if name in self.variables:
return self.variables[name]
elif self.parent:
return self.parent.get(name)
else:
raise NameError(f"未定义的变量: {name}")
def set(self, name: str, value: Any):
"""设置变量值"""
if name in self.variables:
self.variables[name] = value
elif self.parent and self.parent.has(name):
self.parent.set(name, value)
else:
self.variables[name] = value
def has(self, name: str) -> bool:
"""检查变量是否存在"""
return name in self.variables or (self.parent and self.parent.has(name))
class Interpreter:
"""树遍历解释器"""
def __init__(self):
self.global_env = Environment()
self.current_env = self.global_env
# 运算符映射
self.binary_operators = {
'+': operator.add,
'-': operator.sub,
'*': operator.mul,
'/': operator.truediv,
'<': operator.lt,
'>': operator.gt,
'==': operator.eq,
'!=': operator.ne,
}
def interpret(self, statements: List[Statement]) -> Any:
"""解释执行语句列表"""
result = None
for stmt in statements:
result = self.execute(stmt)
return result
def execute(self, stmt: Statement) -> Any:
"""执行语句"""
method_name = f"execute_{type(stmt).__name__}"
method = getattr(self, method_name, self.generic_execute)
return method(stmt)
def generic_execute(self, stmt: Statement) -> Any:
raise NotImplementedError(f"执行未实现: {type(stmt).__name__}")
def evaluate(self, expr: Expression) -> Any:
"""求值表达式"""
method_name = f"evaluate_{type(expr).__name__}"
method = getattr(self, method_name, self.generic_evaluate)
return method(expr)
def generic_evaluate(self, expr: Expression) -> Any:
raise NotImplementedError(f"求值未实现: {type(expr).__name__}")
def evaluate_NumberLiteral(self, expr: NumberLiteral) -> float:
"""求值数字字面量"""
return expr.value
def evaluate_Identifier(self, expr: Identifier) -> Any:
"""求值标识符"""
return self.current_env.get(expr.name)
def evaluate_BinaryOperation(self, expr: BinaryOperation) -> Any:
"""求值二元运算"""
left_value = self.evaluate(expr.left)
right_value = self.evaluate(expr.right)
if expr.operator in self.binary_operators:
op_func = self.binary_operators[expr.operator]
return op_func(left_value, right_value)
else:
raise RuntimeError(f"未知的运算符: {expr.operator}")
def execute_Assignment(self, stmt: Assignment) -> Any:
"""执行赋值语句"""
value = self.evaluate(stmt.value)
self.current_env.set(stmt.target.name, value)
return value
def execute_IfStatement(self, stmt: IfStatement) -> Any:
"""执行if语句"""
condition_value = self.evaluate(stmt.condition)
if self.is_truthy(condition_value):
return self.execute_block(stmt.then_branch)
elif stmt.else_branch:
return self.execute_block(stmt.else_branch)
return None
def execute_WhileStatement(self, stmt: WhileStatement) -> Any:
"""执行while语句"""
result = None
while self.is_truthy(self.evaluate(stmt.condition)):
result = self.execute_block(stmt.body)
return result
def execute_Block(self, stmt: Block) -> Any:
"""执行代码块"""
return self.execute_block(stmt.statements)
def execute_block(self, statements: List[Statement]) -> Any:
"""执行语句块(创建新作用域)"""
# 创建新环境
previous_env = self.current_env
self.current_env = Environment(previous_env)
try:
result = None
for stmt in statements:
result = self.execute(stmt)
return result
finally:
# 恢复环境
self.current_env = previous_env
def is_truthy(self, value: Any) -> bool:
"""判断值的真假"""
if value is None or value is False:
return False
if isinstance(value, (int, float)) and value == 0:
return False
if isinstance(value, str) and value == "":
return False
return True
# 调试解释器:支持单步执行和断点
class DebuggingInterpreter(Interpreter):
"""支持调试的解释器"""
def __init__(self):
super().__init__()
self.breakpoints: set = set()
self.step_mode = False
self.execution_stack: List[str] = []
def set_breakpoint(self, line: int):
"""设置断点"""
self.breakpoints.add(line)
def remove_breakpoint(self, line: int):
"""移除断点"""
self.breakpoints.discard(line)
def enable_step_mode(self):
"""启用单步模式"""
self.step_mode = True
def disable_step_mode(self):
"""禁用单步模式"""
self.step_mode = False
def execute(self, stmt: Statement) -> Any:
"""带调试功能的执行"""
# 记录执行栈
stmt_info = f"{type(stmt).__name__}"
self.execution_stack.append(stmt_info)
# 检查断点和单步模式
if self.step_mode or hasattr(stmt, 'line') and stmt.line in self.breakpoints:
self.debug_pause(stmt)
try:
result = super().execute(stmt)
return result
finally:
self.execution_stack.pop()
def debug_pause(self, stmt: Statement):
"""调试暂停"""
print(f"\n=== 调试暂停 ===")
print(f"语句类型: {type(stmt).__name__}")
print(f"执行栈: {' -> '.join(self.execution_stack)}")
print(f"当前变量:")
# 显示当前环境的变量
env = self.current_env
while env:
for name, value in env.variables.items():
print(f" {name} = {value}")
env = env.parent
# 等待用户输入
while True:
command = input("调试命令 (c=继续, s=单步, v=查看变量, q=退出): ").strip().lower()
if command == 'c':
self.step_mode = False
break
elif command == 's':
self.step_mode = True
break
elif command == 'v':
var_name = input("变量名: ").strip()
try:
value = self.current_env.get(var_name)
print(f"{var_name} = {value}")
except NameError as e:
print(f"错误: {e}")
elif command == 'q':
raise KeyboardInterrupt("用户终止调试")
else:
print("未知命令")
# 使用示例
def demo_interpreter():
source_code = """
x = 10;
y = x + 5 * 2;
if (y > 15) {
z = y - 10;
result = z * 2;
}
"""
print("=== 源代码 ===")
print(source_code)
# 词法分析
lexer = Lexer(source_code)
tokens = lexer.tokenize()
# 语法分析
parser = Parser(tokens)
ast = parser.parse()
# 解释执行
interpreter = Interpreter()
result = interpreter.interpret(ast)
print("\n=== 执行结果 ===")
print(f"最终结果: {result}")
print("\n=== 变量状态 ===")
for name, value in interpreter.global_env.variables.items():
print(f"{name} = {value}")
def demo_debugging_interpreter():
source_code = """
x = 5;
y = 0;
while (x > 0) {
y = y + x;
x = x - 1;
}
"""
print("=== 调试解释器演示 ===")
print("源代码:")
print(source_code)
# 词法分析和语法分析
lexer = Lexer(source_code)
tokens = lexer.tokenize()
parser = Parser(tokens)
ast = parser.parse()
# 调试解释器
interpreter = DebuggingInterpreter()
interpreter.enable_step_mode() # 启用单步模式
try:
result = interpreter.interpret(ast)
print(f"\n程序执行完成,结果: {result}")
print("\n最终变量状态:")
for name, value in interpreter.global_env.variables.items():
print(f"{name} = {value}")
except KeyboardInterrupt:
print("\n调试被用户终止")
if __name__ == "__main__":
demo_interpreter()
print("\n" + "="*50 + "\n")
# demo_debugging_interpreter() # 取消注释以运行调试演示
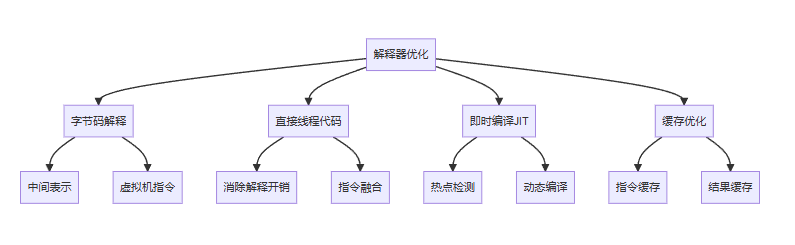
3.3.3 解释器优化技术
解释器优化
字节码解释
直接线程代码
即时编译 JIT
缓存优化
中间表示
虚拟机指令
消除解释开销
指令融合
热点检测
动态编译
指令缓存
结果缓存
3.4 编译与解释的比较
3.4.1 性能对比
xychart-beta
title "编译vs解释性能对比"
x-axis [启动时间, 执行速度, 内存使用, 开发效率, 调试便利性]
y-axis "性能评分" 0 --> 10
bar [2, 9, 7, 6, 4]
bar [8, 4, 5, 9, 8]
3.4.2 详细对比分析
| 特性 | 编译型 | 解释型 | 混合型 |
|---|---|---|---|
| 执行速度 | 很快 | 较慢 | 中等 |
| 启动时间 | 快 | 很快 | 中等 |
| 内存占用 | 小 | 大 | 中等 |
| 开发效率 | 低 | 高 | 中等 |
| 调试便利 | 困难 | 容易 | 中等 |
| 跨平台性 | 差 | 好 | 好 |
| 错误检测 | 编译时 | 运行时 | 混合 |
| 代码保护 | 好 | 差 | 中等 |
3.4.3 适用场景分析
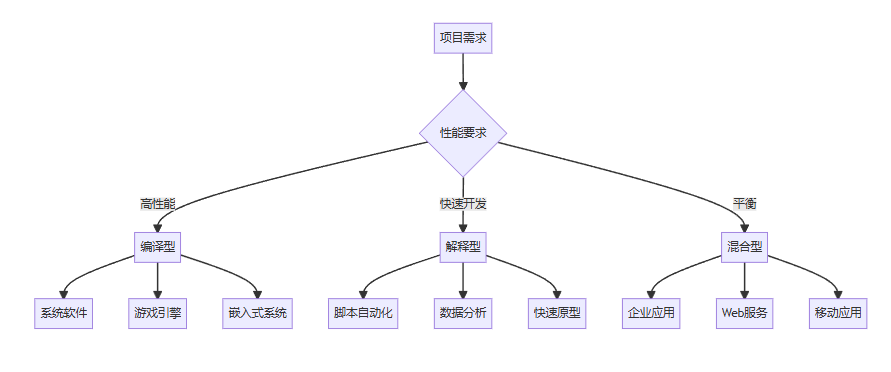
高性能
快速开发
平衡
项目需求
性能要求
编译型
解释型
混合型
系统软件
游戏引擎
嵌入式系统
脚本自动化
数据分析
快速原型
企业应用
Web 服务
移动应用
实践练习
练习 1:简单编译器实现
实现一个支持基本算术运算的简单编译器:
要求:
- 支持加减乘除运算
- 支持变量赋值
- 生成三地址码
- 包含基本的错误处理
测试用例:
a = 10;
b = 20;
c = a + b * 2;
练习 2:解释器扩展
扩展前面的解释器,添加以下功能:
要求:
- 支持函数定义和调用
- 支持数组操作
- 添加内置函数(print, input 等)
- 实现异常处理机制
练习 3:性能测试
编写性能测试程序,比较编译型和解释型语言的执行效率:
测试项目:
- 循环计算(如计算斐波那契数列)
- 递归算法(如快速排序)
- 字符串处理
- 数学计算
分析维度:
- 执行时间
- 内存使用
- CPU 利用率
总结
本章深入探讨了编译和解释的基本原理:
核心要点
- 编译过程:源代码 → 词法分析 → 语法分析 → 语义分析 → 代码生成 → 目标代码
- 解释过程:源代码 → 分析 → 直接执行
- 性能权衡:编译型注重执行效率,解释型注重开发效率
- 现代趋势:混合模式(JIT 编译)平衡了两者的优势
技术发展趋势
- 智能编译:基于机器学习的编译优化
- 增量编译:只编译修改的部分
- 云端编译:利用云计算资源进行编译
- 自适应解释:根据运行时特征动态优化
下一步
理解了编译与解释的基本原理后,下一章我们将详细学习 004 - 编译器处理过程详解,深入了解编译器各个阶段的具体实现技术。